![[chatbot + AI = 下一代操作模式][34]賦予Chatbot用語音下指令以及翻譯的功能.jpg](/posts/2018/08/2018-08-16-bot-framework-with-ai-cognitive-service-34-integrate-speech-command-in-chatbot-and-allow-translation-into-other-language/1aea1117-f82b-47ef-97fc-866df779573f.jpg)
在上一篇([33]C#使用Translator Speech API服務達到語音轉文字加翻譯)瞭解了如何用C# Console使用Translator Speech Api的服務達到語音轉文字加翻譯。那麽要整合到Chatbot就更加沒有問題了。
這一篇將介紹如何把Translator Speech Api整合到Chatbot裡面,語音能夠轉文字就能夠達到用說來叫Chatbot做事,并且提供一些多國語言的使用情景,例如不會說中文的客戶,可以透過chatbot達到及時語音翻譯。
Translator Speech Api整合到Chatbot
要整合到Chatbot和其他幾個有點類似,大概會經歷過幾個步奏:
- 建立Translator Speech Api的Service
- 建立Dialog處理語音邏輯
- 整合到
RootLuisDialog - 測試
建立Translator Speech Api的Service
這個Service代表著物件導向版本的TranslatorSpeechApi,方便呼叫服務。
整個邏輯和上一篇的Console裡面看到的邏輯差不多,這邊比較特別只是建立這個物件的時候需要注入服務的Key。
另外一個是建立出一個Model叫做:ResponseModel,用來接Translator Speech Api的結果。
詳細的程式碼就不發在部落格上面了,詳細請看 :mhat-hotelbot/src/MHAT.HotelBot/Services/TranslatorSpeechService.cs
建立Dialog處理語音邏輯
接下來要建立一個Dialog叫做SpeechTranslationDialog,這個Dialog的主要目的是把Bot Builder SDK得到的内容做處理,然後呼叫TranslatorSpeechService做語音轉文字和翻譯的處理。
這邊要注意一下,一般來説模擬器可以直接發語音做測試,但是可能是我電腦問題,兩個版本的模擬器都無法使用語音,因此我用了一個自定的格式,這個内容格式是:media@{語音檔案路徑}。
因此,這邊的Dialog會用這個格式做處理,整個的邏輯如下:
[Serializable]
public class SpeechTranslationDialog : IDialog<List<ResponseModel>>
{
public async Task StartAsync(IDialogContext context)
{
await context.PostAsync("請輸入:media@RecordMediaPath");
context.Wait(MessageReceivedAsync);
}
private async Task MessageReceivedAsync
(IDialogContext context,
IAwaitable<IMessageActivity> inResult)
{
var activity = context.Activity as IMessageActivity;
var textSplit = activity.Text.Split('@');
var mediaUrl = textSplit.Last();
var tranlsatorService =
new TranslatorSpeechService
(ConfigurationManager
.AppSettings["TranslatorSpeechApiKey"]);
var result = await tranlsatorService
.TranslateSpeech(mediaUrl);
context.Done(result);
}
}整合到RootLuisDialog
接下來就是要把整個組合在一起了。
首先在luis.ai的網站加入一個intent叫做SpeechRecognizer,裡面有個utterance叫做語音,記得要train以及publish模型:
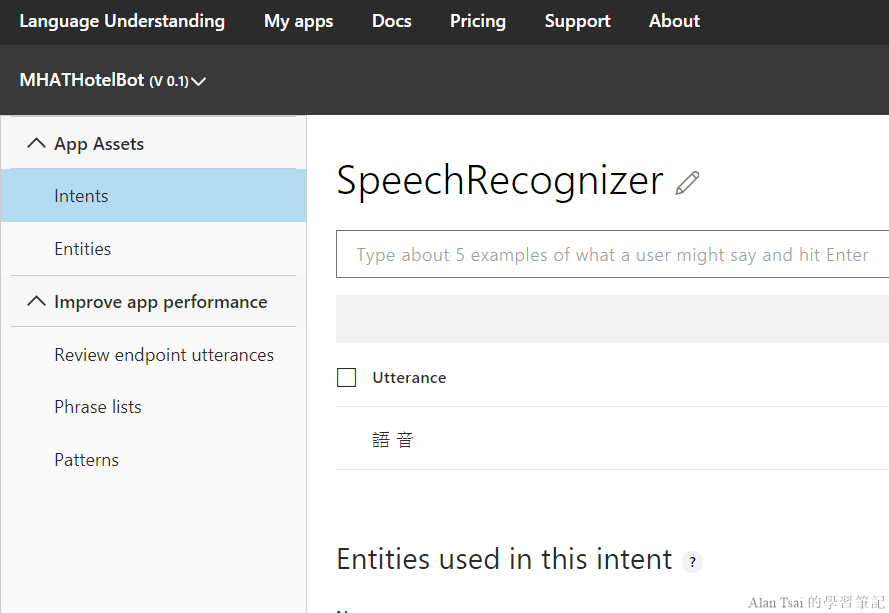
接下來就是調整RootLuisDialog呼叫語音的dialog:
[LuisIntent("SpeechRecognizer")]
public Task SpeechRecognizer
(IDialogContext context, LuisResult result)
{
context.Call(new SpeechTranslationDialog(),
SpeechRecognizerAfterAsync);
return Task.CompletedTask;
}
private async Task SpeechRecognizerAfterAsync
(IDialogContext context, IAwaitable<List<ResponseModel>> result)
{
var finalResult = await result;
await context.PostAsync($"識別:{finalResult.First().recognition}");
await context.PostAsync($"翻譯:{finalResult.First().translation}");
context.Wait(MessageReceived);
}測試結果
接下來就是做測試的時候了,透過模擬器測試整個功能:
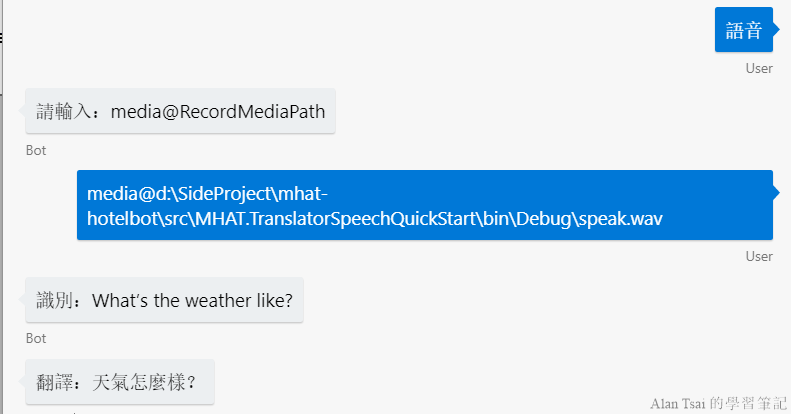
上圖使用的範例語音檔案就是上一篇的範例程式碼裡面用到的speak.wav檔案。
可以看到識別出文字并且翻譯和上一篇的console程式結果一致。
下一步調整
到這邊爲止也就是今天的全部内容,不過其實這邊的程式碼還有很多進步的空間,或者説有更多可以整合的地方,這邊列出來給大家未來使用上面做參考:
- 既然語音可以識別出文字了,那是否可以用語音的方式下指令,然後先透過語音轉文字,再用文字到luis判斷出intent然後在執行指令
- Translator Speech Api有限制語音格式,因此,應該要檢查好格式,必要時轉檔的邏輯整合進去
結語
這篇介紹了如何把Translator Speech Api整合進入了chatbot裡面。透過這個範例,可以瞭解如何實際整合運用,并且在最後面給出了一些未來要上production需要考慮到的地方。
到了這篇,這個系列就快要進入了尾聲,這系列把常見的自然輸入方式都介紹了一輪:
- 文字
- 透過LUIS來找到intent
- 圖像
- 用了圖像識別以及OCR的服務讓拍照的方式查找飲料費用以及發票識別。
- 語音
- 可以把語音轉成文字,達到語音下達指令的方式。以及語音直接從一個語言翻譯到另外一個語言提供更多元的功能。
Cognitive Service還有很多其他的服務,有些服務甚至是多個服務組合或者某個服務加强在產生出來的。在接下來的篇章將對其中幾個做介紹。
在下一篇([35]使用QnA Maker打造問答知識類型資料集服務)將介紹其中一個,QnA Maker,方便做知識庫類型的服務。





_1477.png)
_1485.png)
_1486.png)