![[chatbot + AI = 下一代操作模式][27]Custom Vision - 自己的Model自己Train 建立圖片的分類模型.jpg](/posts/2018/08/2018-08-06-bot-framework-with-ai-cognitive-service-27-use-custom-vision-to-train-your-image-classifier/bdff832d-ff2b-49c0-8ba3-dea496a8bca6.jpg)
上一篇([26]賦予chatbot OCR的能力 - 加入對發票的功能)介紹完了Computer Vision裡面的OCR服務整合到Bot Builder SDK的程式了之後,來看看另外一個和Vision有關的服務,Custom Vision。
在這一篇將介紹Custom Vision是一個什麽樣的服務,并且如何用Custom Vision來建立一個之後會用到的模型。
Custom Vision是什麽?
還記得Computer Vision在介紹的時候提到,那個服務是由微軟用了非常大量的圖片train出來的模型,用來做通用圖片辨識的服務。
可是,每一個使用情景不同,可能會有自己domain的圖片,這個時候Computer Vision就太Generic導致無法很好的識別這些特定領域的圖片。
那有沒有其他的解決方案呢?既然微軟Train出來的是Generic的模型,難道沒辦法自己提供圖片做Training嗎?
這個就是Custom Vision出現的原因,自己的模型自己Train,最後Train出來才符合自己的Domain使用。
Custom Vision是在train什麽模型?
上面一直提到train自己的模型,可是這個train出來的模型目的是什麽?
Custom Vision有兩個目的:
- Train出一個能夠分類(classifier)的模型
- 能夠從圖片找到物體的範圍 - 目前在preview,這幾篇不會介紹這個功能
如果沒有接觸過Machine Learning可能對於分類還是沒什麽概念,那麽換成HotelBot的情景看看:
從上面的情景可以發現需求是,把拍照的内容做分類,判斷出屬於那一類的飲料,因此Custom Vision非常適合這個工作。
在Custom Vision建立模型
上面瞭解了服務的用途以及概念了之後,接下來看看如何建立一個模型。
要建立模型總共經歷幾個步奏:
- 找訓練資料 - 每一種分類至少準備5張相片
- 在customvision.ai建立一個專案
- 在專案裡面開始上傳training的圖片
- 執行Train的動作
- 測試
找訓練資料
首先是需要找素材,這邊我將對於3個類型的飲料去網路上面找一些圖片:
- 可口可樂
- 百事可樂
- 雪碧
Training的圖片越多越好,至少5張爲好,當然不夠也沒關係,只是準確度有差。
另外一個是在production的時候,最好有些圖片是真實拍出來會比較好,因爲有些網上圖片特徵太明顯會造成之後識別不準確。
在customvision.ai建立一個專案
Custom Vision和LUIS非常類似,都是到某個網站建立一個專案之後才做,因此:
先到https://customvision.ai/主頁,然後按下Sign in的按鈕,登入帳號了之後會看到專案的畫面:
- 如果帳號有多個Azure Subscription的話,右上角可以切換
- 建立新的專案選擇
New Project,如果是調整現有的點選列出來的專案即可

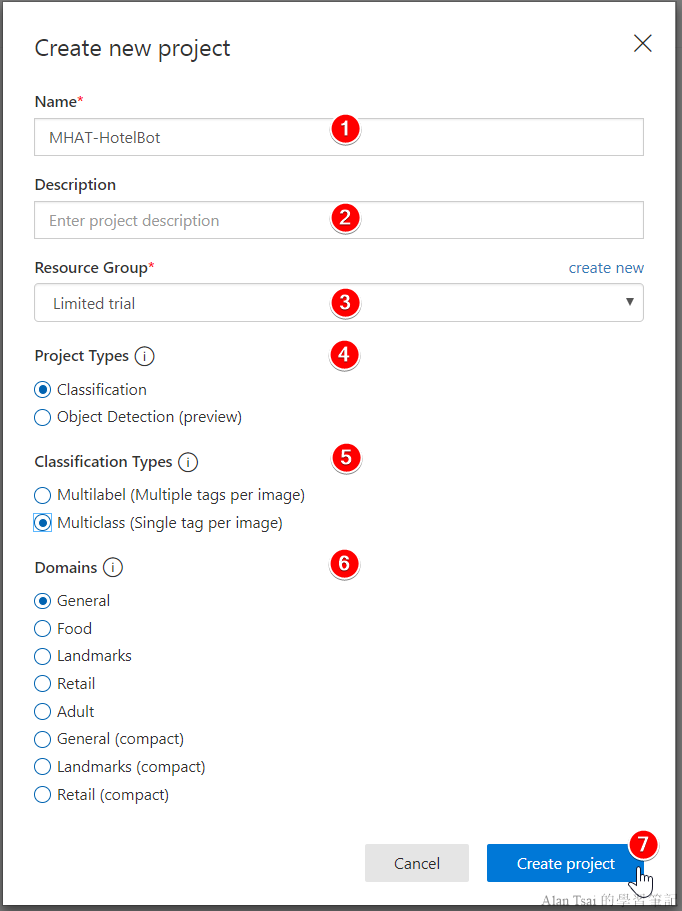
點下New Project之後,有一些欄位需要做填寫:
- Name:好識別即可
- Description:詳細描述,給自己看的
- Resource Group:牽扯到模型建立在那邊,有免費可以用,如果要production就要放在付費的等級比較好。可以選擇旁邊的
Create new來建立 - Project Types:還記得之前提到這個服務有兩個作用,這邊關注classification(分類)的功能
- Classification Types:決定一張圖片能不能有多個標簽,以我們的例子一張圖片一個標簽,因此選2
- Domains:如果圖片屬於某個領域可以選。有括弧
compact表示比較輕量,適合匯出到ios/android的時候選 - Create Project:沒問題之後就點下將會開始建立
在專案裡面開始上傳training的圖片
專案有了之後,就可以開始Train模型。
透過Add Image的按鈕,可以選擇要上傳的圖片,例如要設定可口可樂:
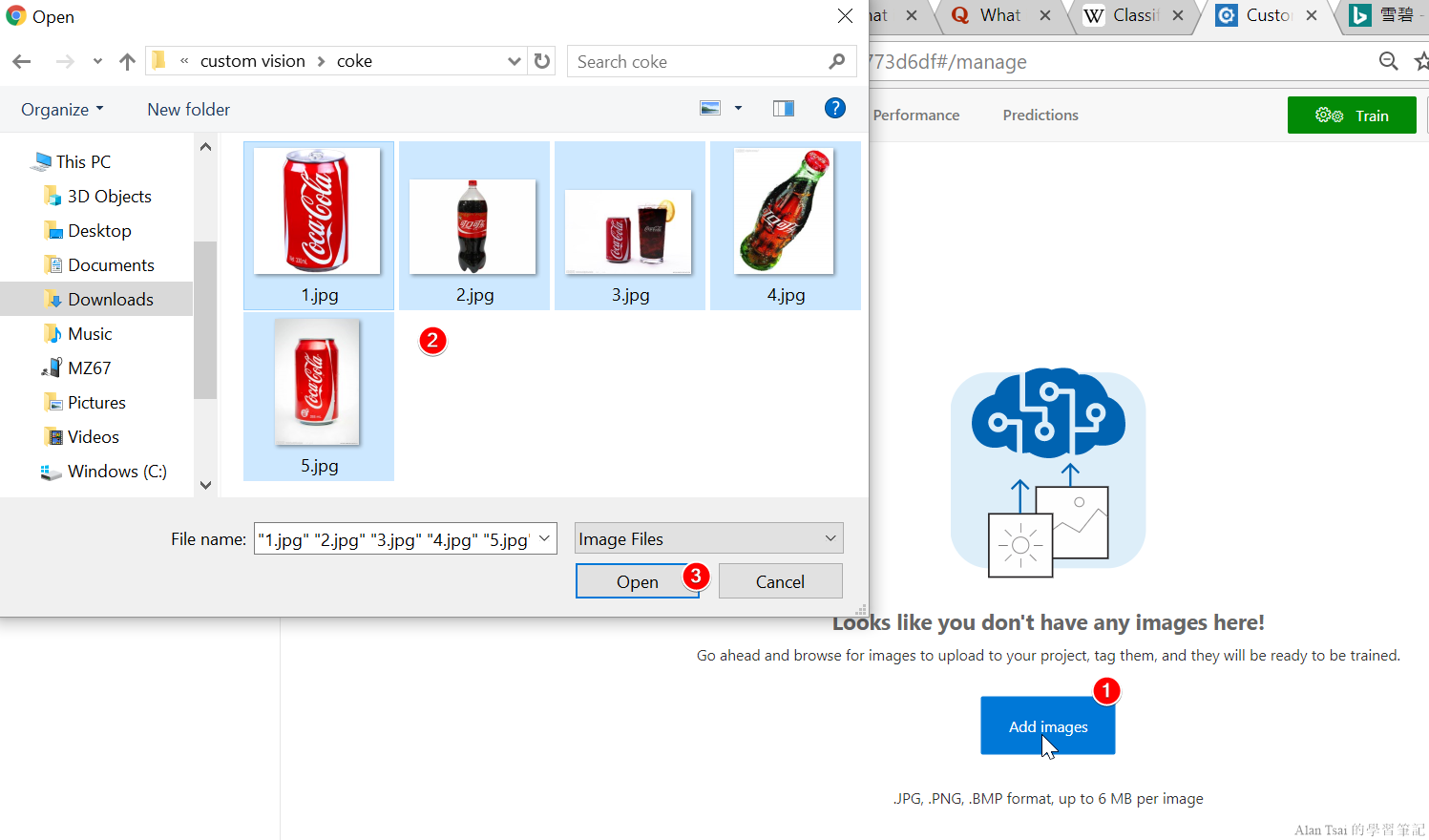
再來要對這些圖片設定一個標簽,這邊輸入了coke,然後按下upload
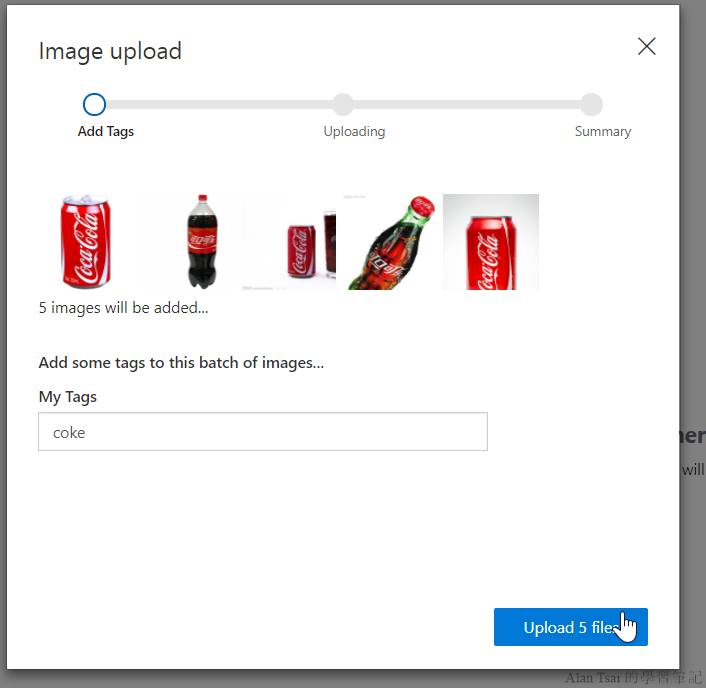
稍等一下,上傳成功的話按鈕會變成Done:
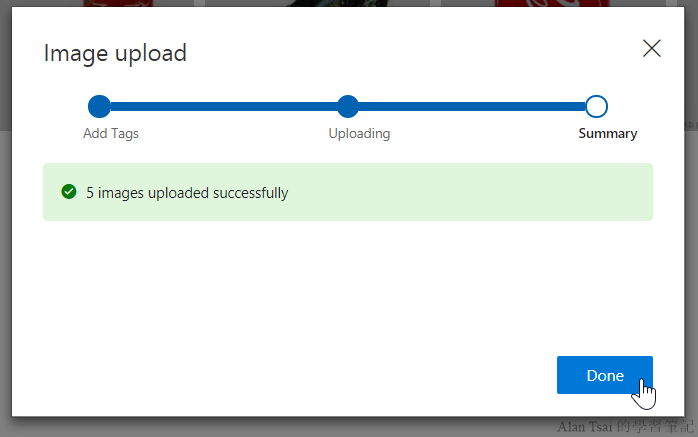
按下Done之後,pop up就不見了,這個時候:
- 剛剛上傳的圖片會顯示出來
- 在左邊可以對這些圖片做篩選
- 透過按鈕
Add images可以增加更多的圖片做training
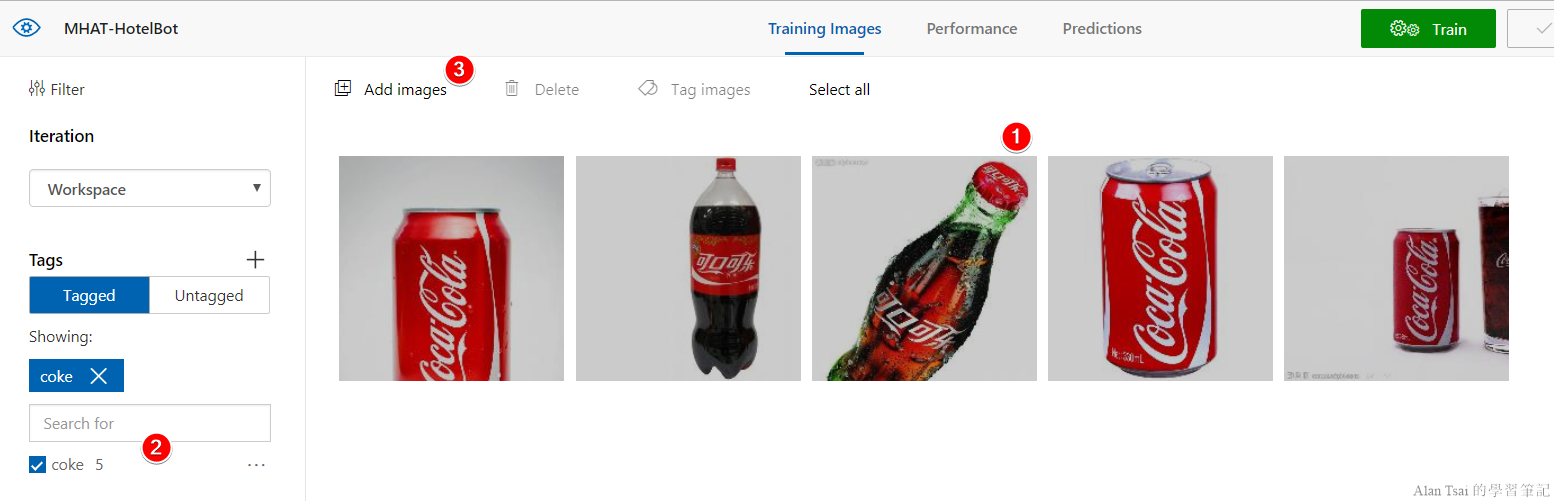
重複把其他兩個飲料也處理了,接下來就可以準備做training了。
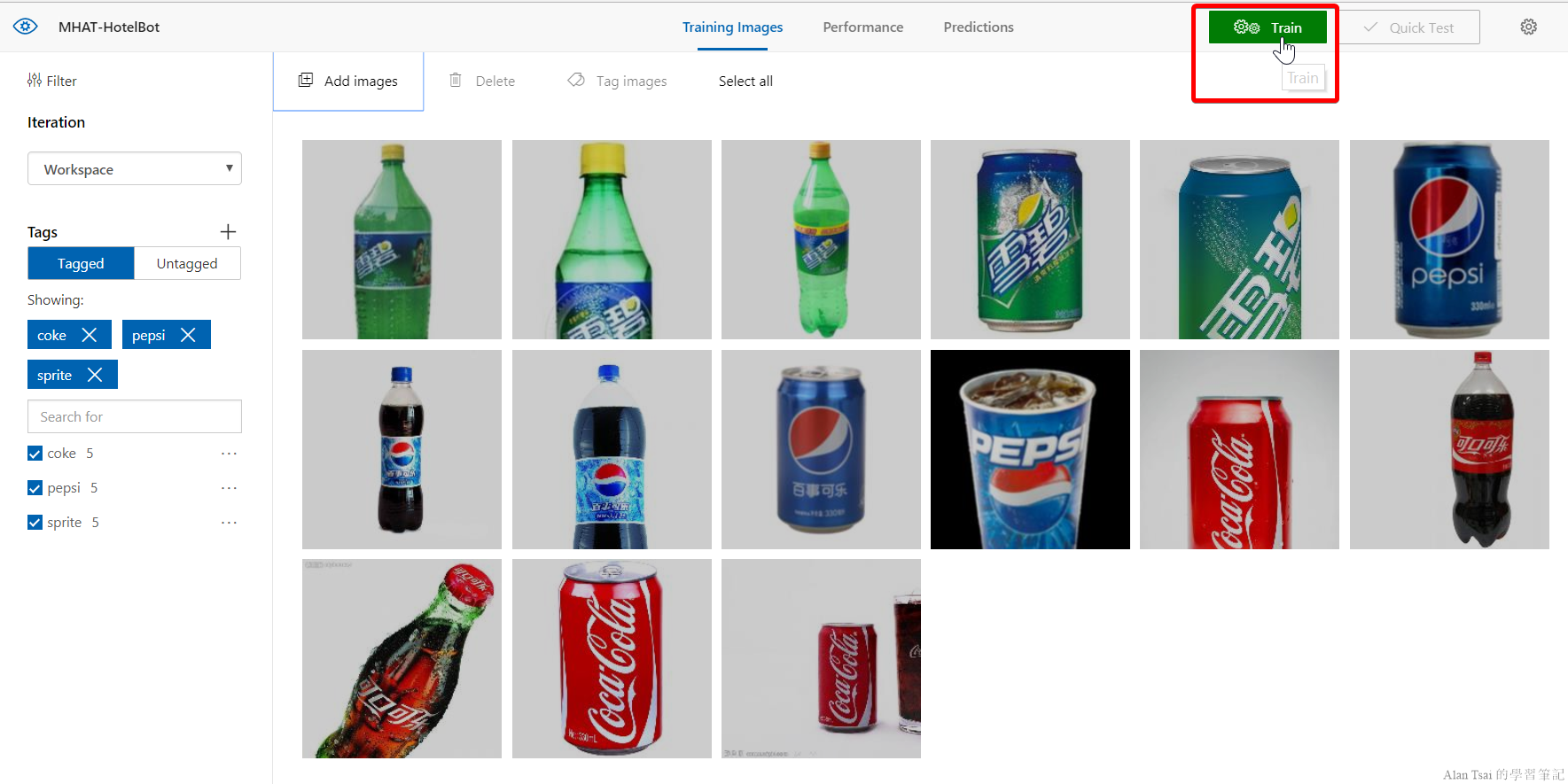
執行Train的動作
接下來就按右上角的Train按鈕即可:
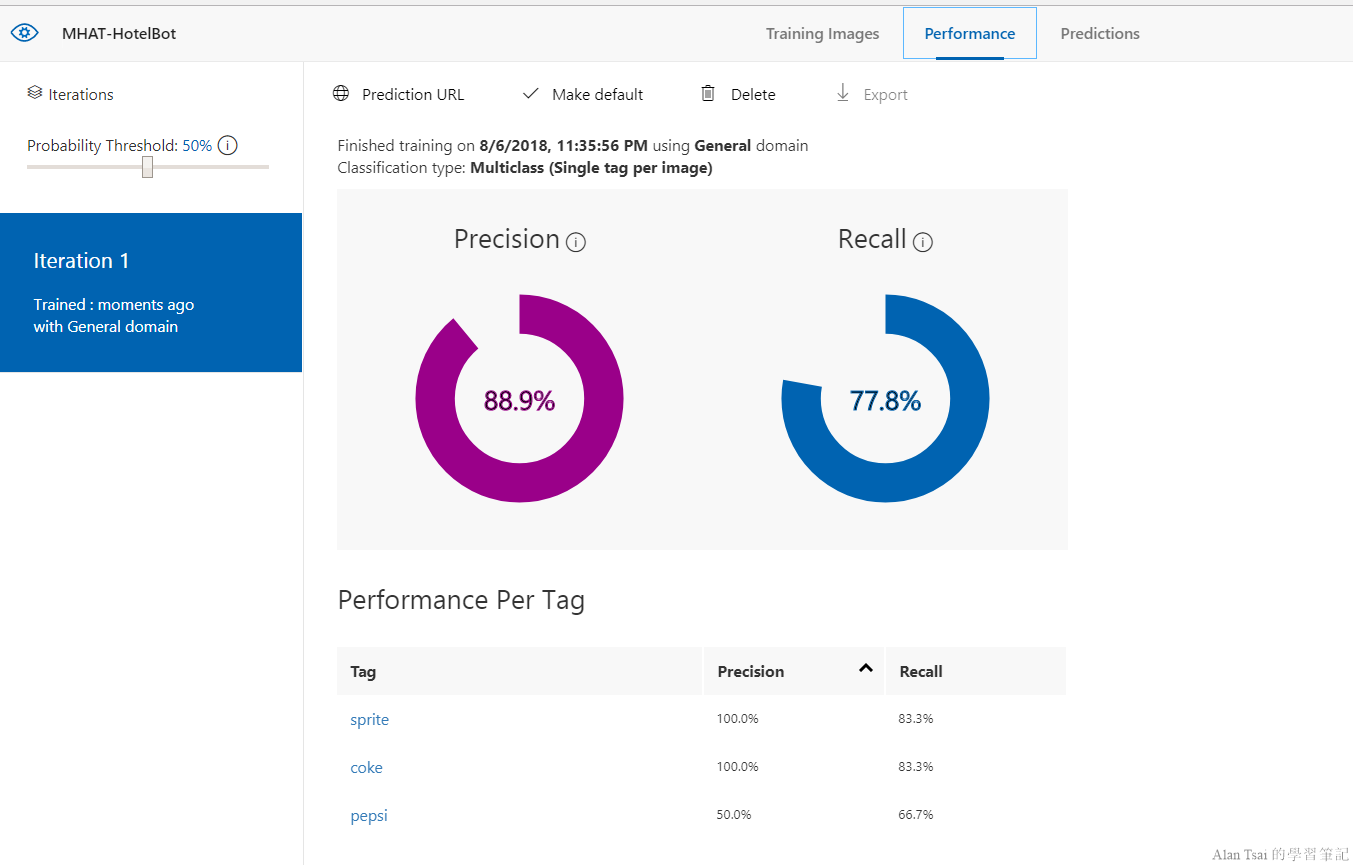
稍等一下,畫面會自動切換到Performance的部分,并且會看到關於這次train完的Precision和Recall:
測試
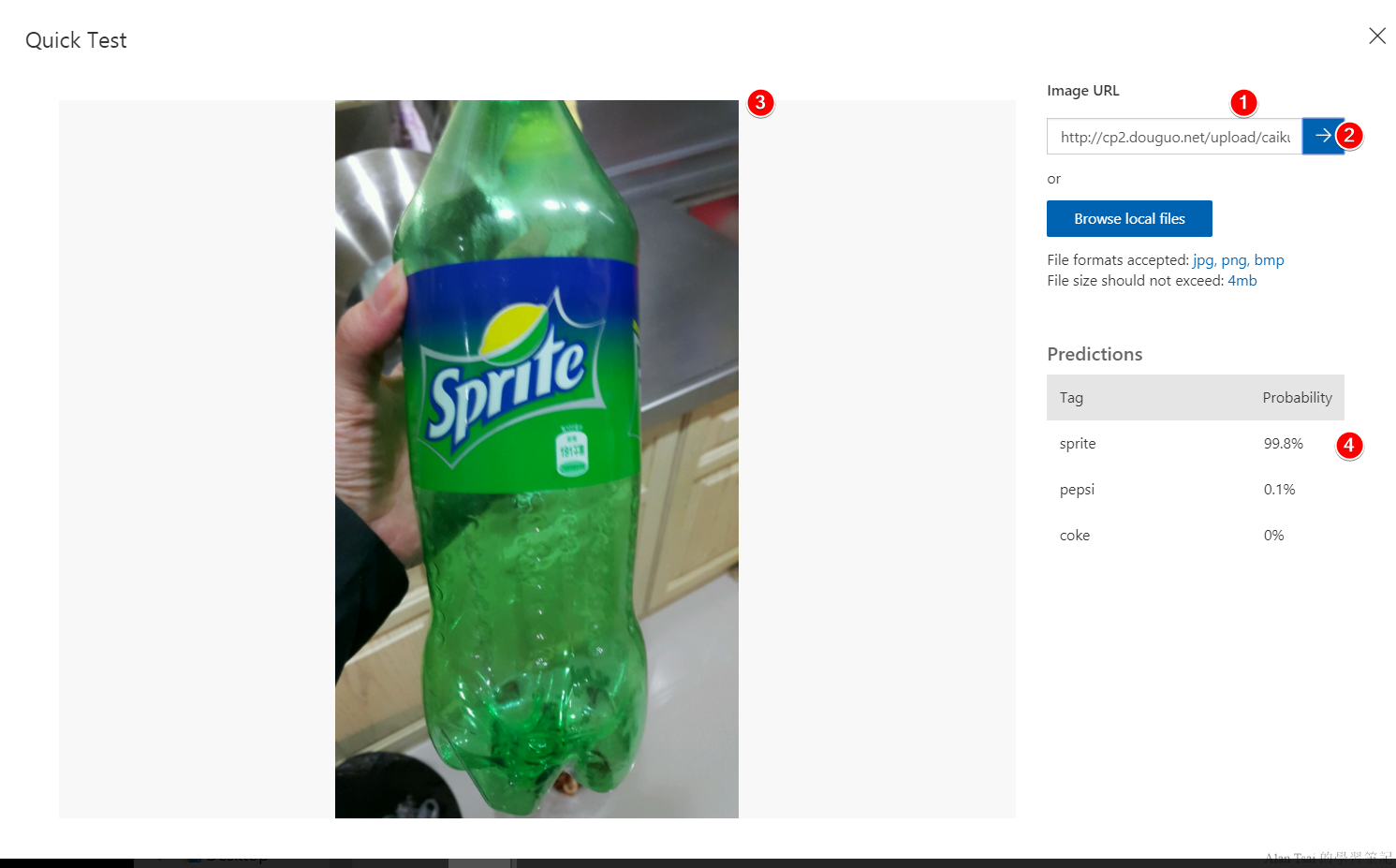
接下來就是測試模型的實際運行會如何,透過按下右上角的Quick Test,這個時候會多出一個pop up,可以用圖片上傳,或者直接給圖片網址的方式給測試。
這邊用了一張人把雪碧拿在手上的相片做測試:
- 首先輸入圖片的網址
- 按下往右的箭頭執行測試
- 左邊會顯示這張圖片的樣子
- 右下角會出現分類的概率 - 可以看到辨識出了sprite
結語
這篇介紹了Custom Vision這個服務的目的以及用途。并且給出了一個測試情景,透過照片告訴客人這個飲料的費用是多少。
依照這個情景,找了圖片,并且實際看看如何在Custom Vision裡面建立出模型并且做測試。
在這個過程,其實會發現操作起來和LUIS非常類似,因此有了LUIS的概念,上手應該沒什麽問題。
下一篇([28]整合Custom Vision到chatbot - 拍照就可以識別價錢)將整合到chatbot裡面,看看如何讓chatbot告訴使用者拍的飲料是多少錢。





_1477.png)
_1485.png)
_1486.png)